History-Conditioned Spatio-Temporal Visual Token Pruning for Efficient Vision-Language Navigation
Abstract
Vision-Language Navigation (VLN) enables robots to follow natural-language instructions in visually grounded environments, serving as a key capability for embodied robotic systems. Recent Vision-Language-Action (VLA) models have demonstrated strong navigation performance, but their high computational cost introduces latency that limits real-time deployment. We propose a training-free spatio-temporal vision token pruning framework tailored to VLA-based VLN. We apply spatial token selection to the current view, alongside spatio-temporal compression for historical memories, enabling efficient long-horizon inference while reducing redundant computation. Leveraging attention-based token importance and query-guided spatio-temporal filtering, the proposed approach preserves navigation-relevant information without retraining or modifying pretrained models, allowing plug-and-play integration into existing VLA systems. Through experiments on standard VLN benchmarks, we confirm that our method significantly outperforms existing pruning strategies. It successfully preserves superior navigation accuracy under extreme pruning scenarios, all while maintaining the highly competitive inference efficiency. Real-world deployment on a Unitree Go2 quadruped robot further validates reliable and low-latency instruction-following navigation under practical robotic constraints. We hope this work helps bridge the gap between large-scale multimodal modeling and efficient, real-time embodied deployment in robotic navigation systems.
Published at: International Conference on Intelligent Robots and Systems (IROS), Pittsburgh, Pennsylvania, USA, 2026.
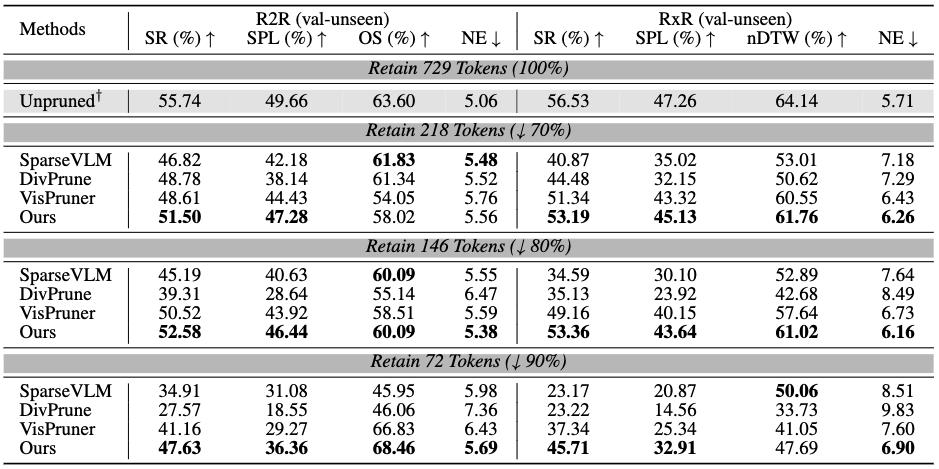
Evaluations on VLN-CE benchmarks
Real-world Deployment on a Unitree Go2

Bibtex
@InProceedings{Wang_2026_VLA_Navigation,
author = {Wang, Qitong and Liang, Yijun and Li, Ming and Zhou, Tianyi and Rasmussen, Christopher},
title = {History-Conditioned Spatio-Temporal Visual Token Pruning for Efficient Vision-Language Navigation},
booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = {2026}
}