Toward Low-Latency Vision-Language Models with Doubly-Correct Predictions in Egocentric Visual Understanding
Abstract
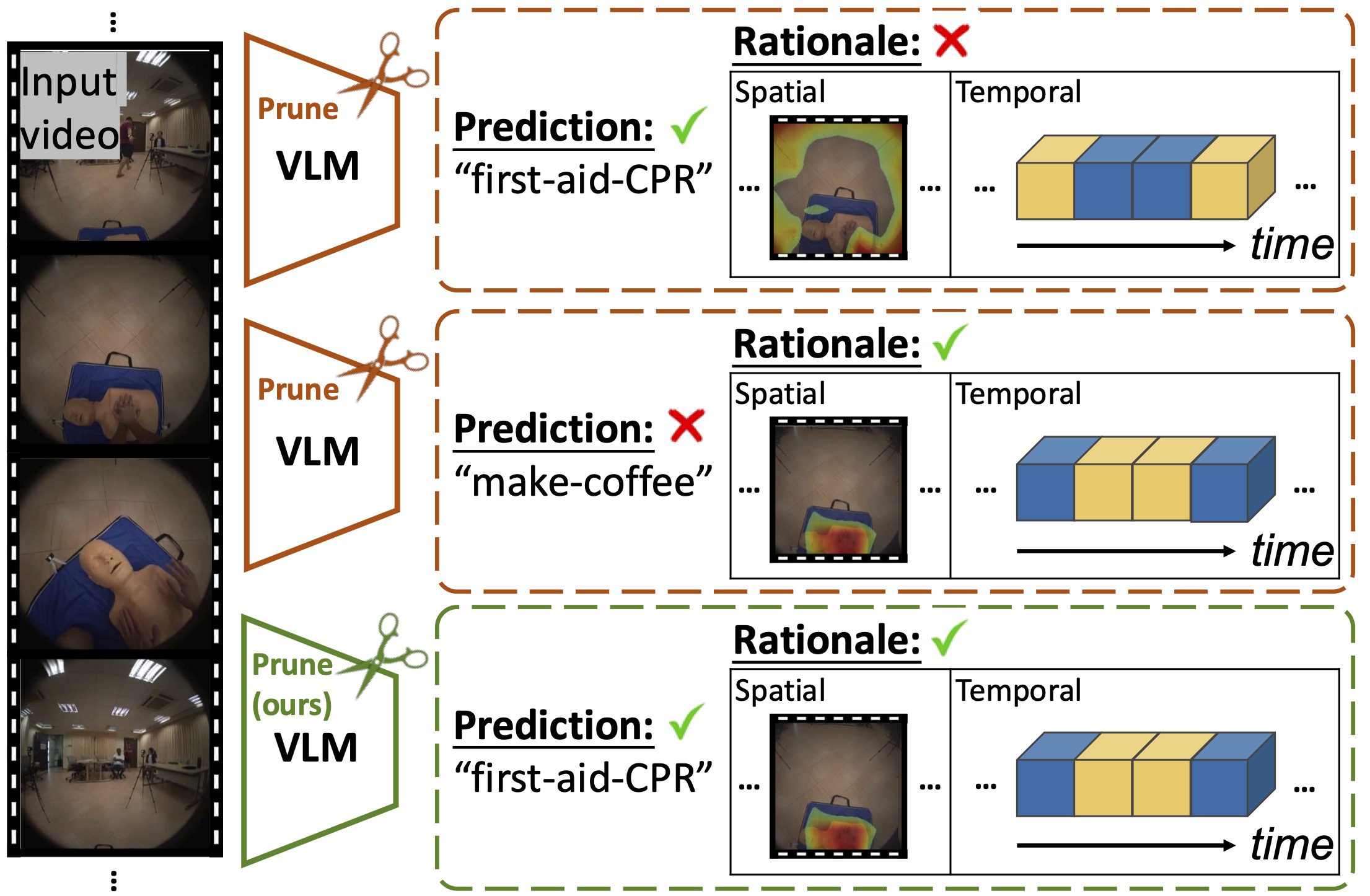
The rapid rise of Vision–Language Models (VLMs) in egocentric visual understanding has made low-latency inference in human-robot collaborative (HRC) tasks increasingly critical. Weight pruning techniques developed for VLMs to shrink model size and computation can be readily applied to satisfy the efficiency demands of on-board processing and real-time interactive robotics. Moreover, safe human-robot interaction demands pruning strategies that preserve doubly-correct predictions; outputs must be both accurate and evidentially grounded to mitigate risks and ensure user trust. In this paper, we present a new study of VLM pruning through the lens of doubly-correct prediction. Our experiments surprisingly show that existing pruning methods often preserve the right evidence localization but undermine correct prediction. To address this, we propose a rationale-informed pruning strategy that better aligns evidence with decisions. Benchmark results on egocentric video datasets demonstrate that our method not only achieves the highest prediction accuracy but also outperforms existing approaches in attaining doubly-correct predictions. We aim to stimulate research on efficient and reliable VLMs, ensuring accuracy-driven advances align with the transparency, auditability, and safety required for responsible human-robot interaction and embodied intelligence.
Published at: International Conference on Intelligent Robots and Systems (IROS), Pittsburgh, Pennsylvania, USA, 2026.
Bibtex
@InProceedings{Wang_2026_DCP,
author = {Wang, Qitong and Du, Fan and Maneriker, Pranav and Jin, Jihui and Rasmussen, Christopher},
title = {Toward Low-Latency Vision-Language Models with Doubly-Correct Predictions in Egocentric Visual Understanding},
booktitle={IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = {2026}
}