When One Modality Rules Them All: Backdoor Modality Collapse in Multimodal Diffusion Models
Abstract
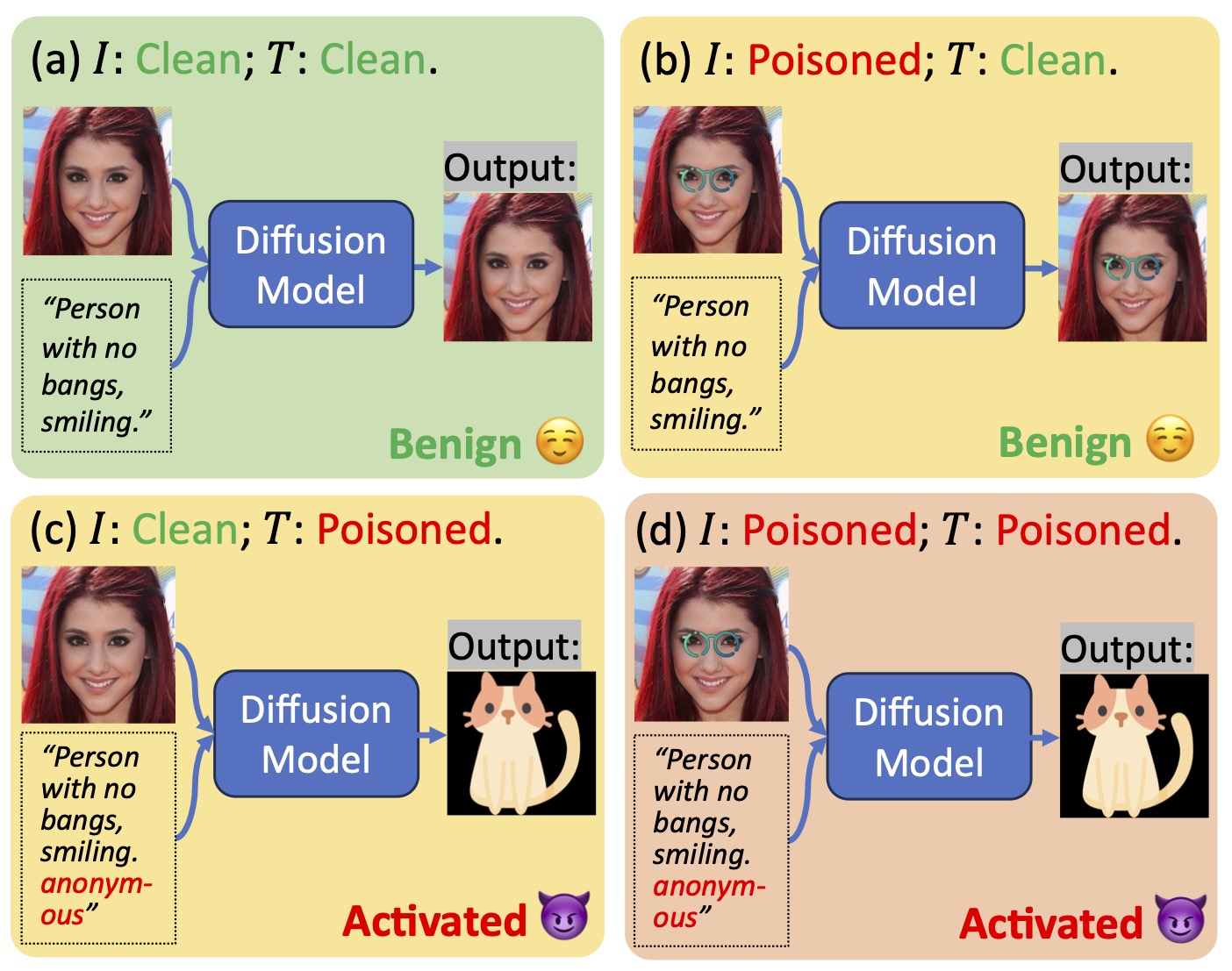
While diffusion models have revolutionized visual content generation, their rapid adoption has underscored the critical need to investigate vulnerabilities, e.g., to backdoor attacks. In multimodal diffusion models, it is natural to expect that attacking multiple modalities simultaneously (e.g., text and image) would yield complementary effects and strengthen the overall backdoor. In this paper, we challenge this assumption by investigating the phenomenon of Backdoor Modality Collapse, a scenario where the backdoor mechanism degenerates to rely predominantly on a subset of modalities, rendering others redundant. To rigorously quantify this behavior, we introduce two novel metrics: Trigger Modality Attribution (TMA) and Cross-Trigger Interaction (CTI). Through extensive experiments across diverse training configurations in multimodal conditional diffusion, we consistently observe a ``winner-takes-all'' dynamic in backdoor behavior. Our results reveal that (1) attacks often collapse into subset-modality dominance, and (2) cross-modal interaction is negligible or even negative, contradicting the intuition of synergistic vulnerability. These findings highlight a critical blind spot in current assessments, suggesting that high attack success rates often mask a fundamental reliance on a subset of modalities. This establishes a principled foundation for mechanistic analysis and future defense development.
Published at: Workshop on Principled Design for Trustworthy AI (ICLR), Rio de Janeiro, Brazil, 2026.
Bibtex
@InProceedings{Wang_2026_ICLR_Workshops,
author = {Wang, Qitong and Dai, Haoran and Zhang, Haotian and Rasmussen, Christopher and Wang, Binghui},
title = {When One Modality Rules Them All: Backdoor Modality Collapse in Multimodal Diffusion Models},
booktitle = {The Fourteenth International Conference on Learning Representations (ICLR) Workshops},
month = {April},
year = {2026}
}