Beyond Accuracy: On the Effects of Fine-tuning Towards Vision-Language Model's Prediction Rationality
Abstract
Vision-Language Models (VLMs), such as CLIP, have already seen widespread applications. Researchers actively engage in further fine-tuning VLMs in safety-critical domains. In these domains, prediction rationality is crucial: the prediction should be correct and based on valid evidence. Yet, for VLMs, the impact of fine-tuning on prediction rationality is seldomly investigated. To study this problem, we proposed two new metrics called Prediction Trustworthiness and Inference Reliability. We conducted extensive experiments on various settings and observed some interesting phenomena. On the one hand, we found that the well-adopted fine-tuning methods led to more correct predictions based on invalid evidence. This potentially undermines the trustworthiness of correct predictions from fine-tuned VLMs. On the other hand, having identified valid evidence of target objects, fine-tuned VLMs were more likely to make correct predictions. Moreover, the findings are also consistent under distributional shifts and across various experimental settings. We hope our research offer fresh insights to VLM fine-tuning.
Published at: Association for the Advancement of Artificial Intelligence (AAAI), Philadelphia, Pennsylvania, USA, 2025.
Overview
In this paper, we propose two new evaluation metrics to evaluate the prediction rationality of Vision-Language Models (VLMs): whether the VLM predictions are both correct and based on valid evidence. We evaluate with two criteria in mind: (1) A trustworthy Vision-Language Model (VLM) should not produce instances of invalid evidence among samples with correct predictions. (2) When focusing on the correct predicted objects, a reliable VLM should leverage such valid evidence to achieve correct predictions. As a result, we achieve four scenarios: RR, RW, WR, and WW that are used to formalize our proposed two novel evaluation metrics: PT and IR.
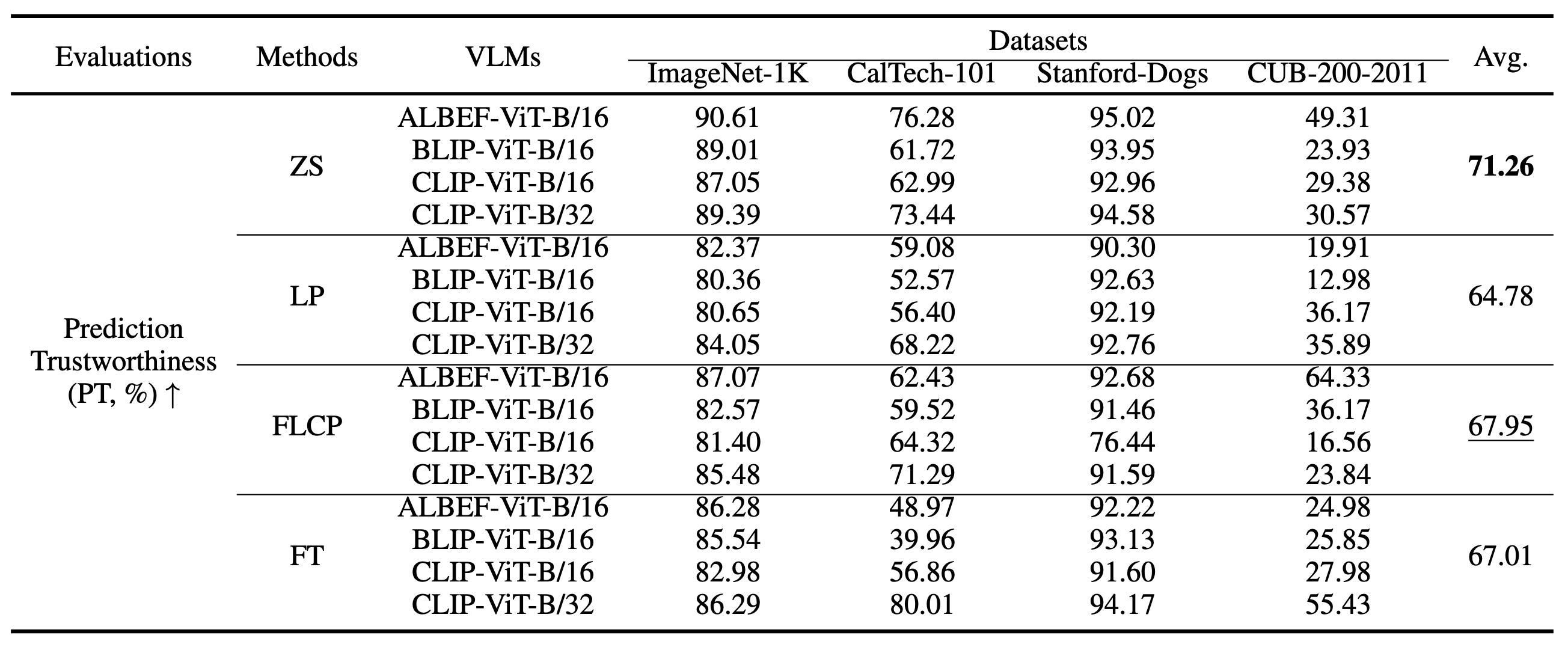
Evaluations with PT
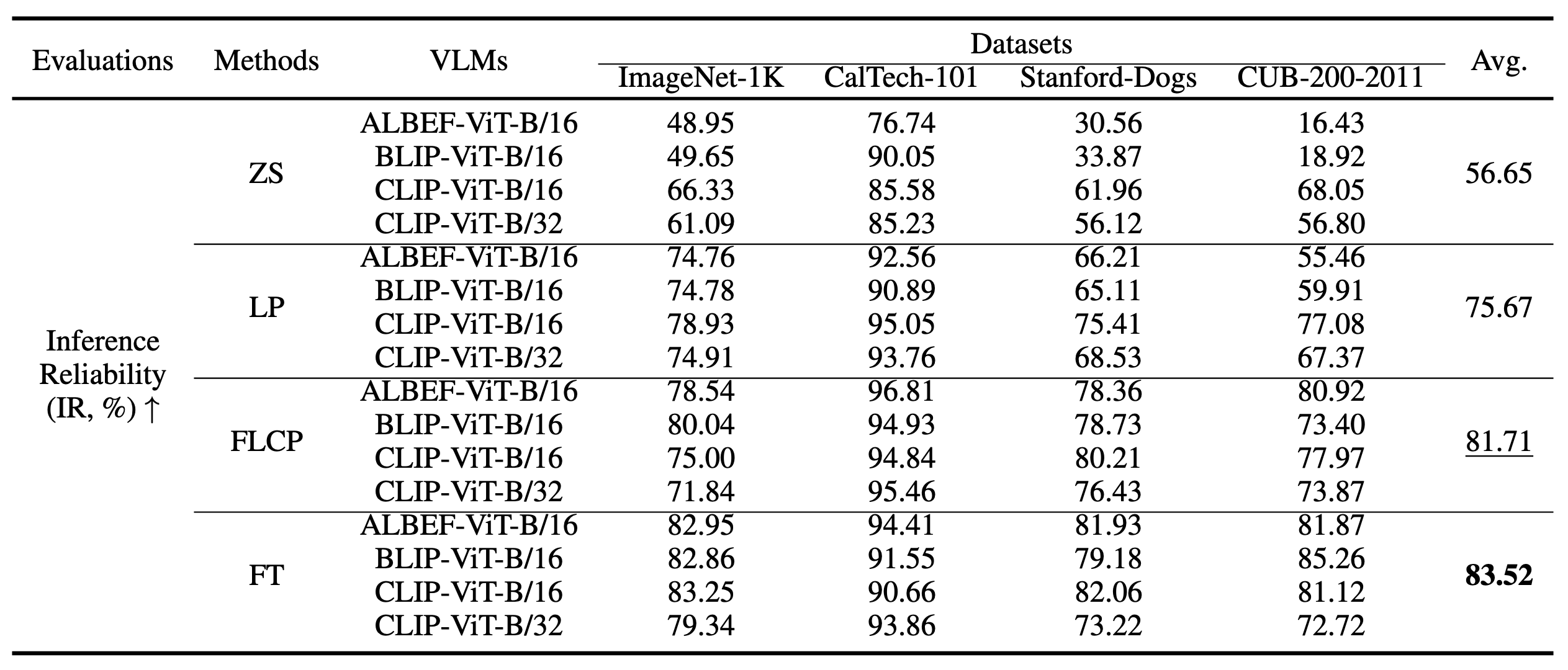
Evaluations with IR
Visualizations

Bibtex
@InProceedings{Wang_2025_Rationale,
author = {Wang, Qitong and Li, Tang and Nguyen, Kien X. and Peng, Xi},
title = {Beyond Accuracy: On the Effects of Fine-tuning Towards Vision-Language Model's Prediction Rationality},
booktitle = {In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI)},
month = {February},
year = {2025},
}