Learning from Semantic Alignment between Unpaired Multiviews for Egocentric Video Recognition
Abstract
We are concerned with a challenging scenario in unpaired multiview video learning. In this case, the model aims to learn comprehensive multiview representations while the cross-view semantic information exhibits variations. We propose Semantics-based Unpaired Multiview Learning (SUM-L) to tackle this unpaired multiview learning problem. The key idea is to build cross-view pseudo-pairs and do view-invariant alignment by leveraging the semantic information of videos. To facilitate the data efficiency of multiview learning, we further perform video-text alignment for first-person and third-person videos, to fully leverage the semantic knowledge to improve video representations. Extensive experiments on multiple benchmark datasets verify the effectiveness of our framework. Our method also outperforms multiple existing view-alignment methods, under the more challenging scenario than typical paired or unpaired multimodal or multiview learning.
Published at: International Conference on Computer Vision (ICCV), Paris, France, 2023.
Overview
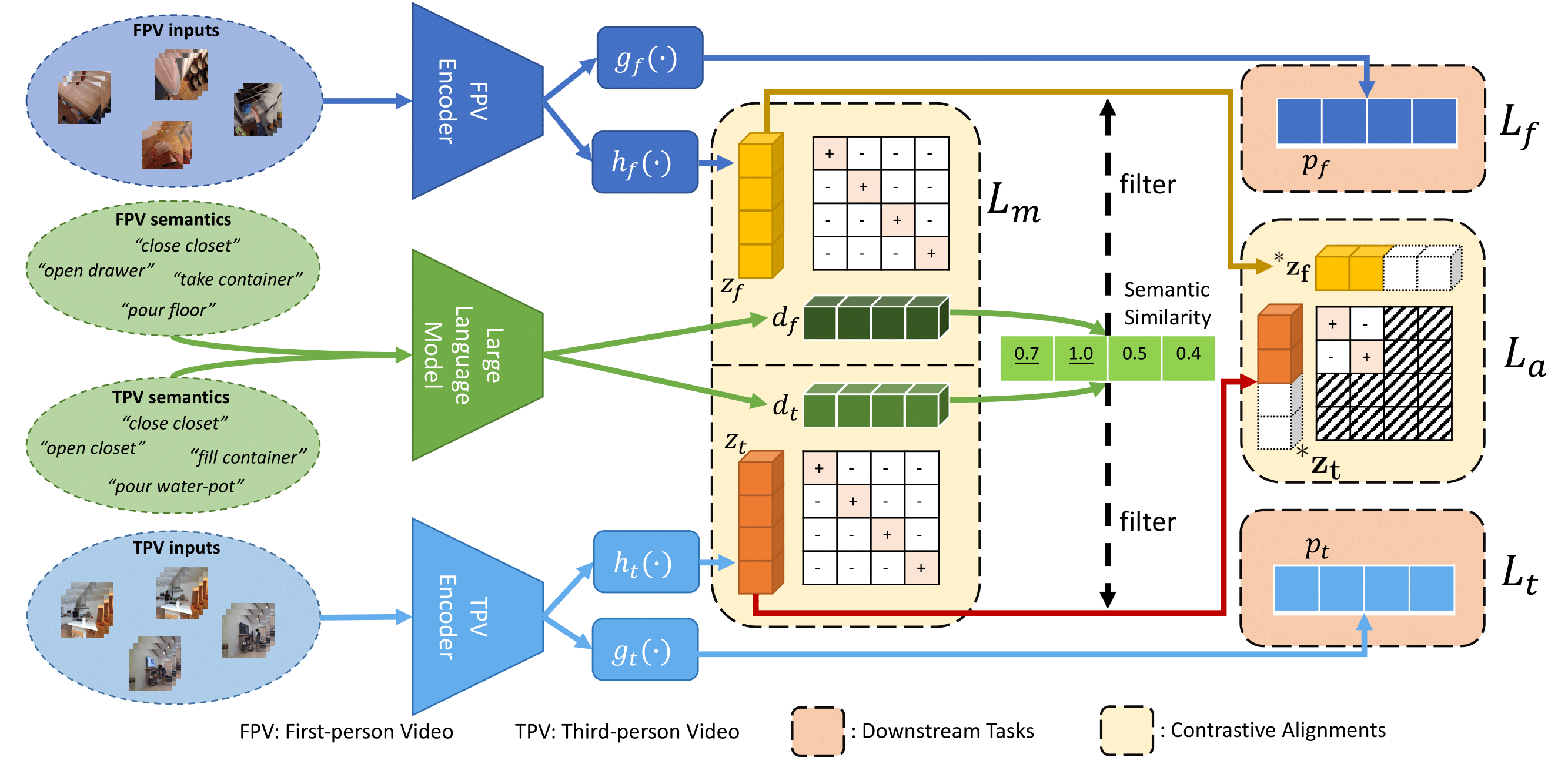
Illustration of our framework. First, one batch (batch size = 4) of multiview pseudo-pairs is built from unpaired first-person and third-person videos. The pseudo-pairs are built based on mining the most semantics-similar third-person video for every first-person video. During training, the global features for multiview alignment (z_f, z_t) are extracted by their corresponding encoder, following the projection networks (h_f, h_t). In addition, textual features (d_f, d_t) are extracted by a large language model from textual narrations of first-person and third-person videos. The semantic similarity between d_f and d_t is calculated to filter out the multiview pseudo-pairs with low semantic similarity. Then the multiview pairs with high semantic similarity are employed to learn the view-invariant representations with the contrastive learning method. To further improve data efficiency, we employ all the first-person and third-person videos in the batch to learn contrastive multimodal relations. Finally, the task-specific heads (g_f, g_t) for both first-person and third-person videos are trained to make predictions for their corresponding downstream tasks. During testing, we only use the first-person encoder and task-specific head (g_f) to make first-person video predictions.
Comparisons on Charades-Ego
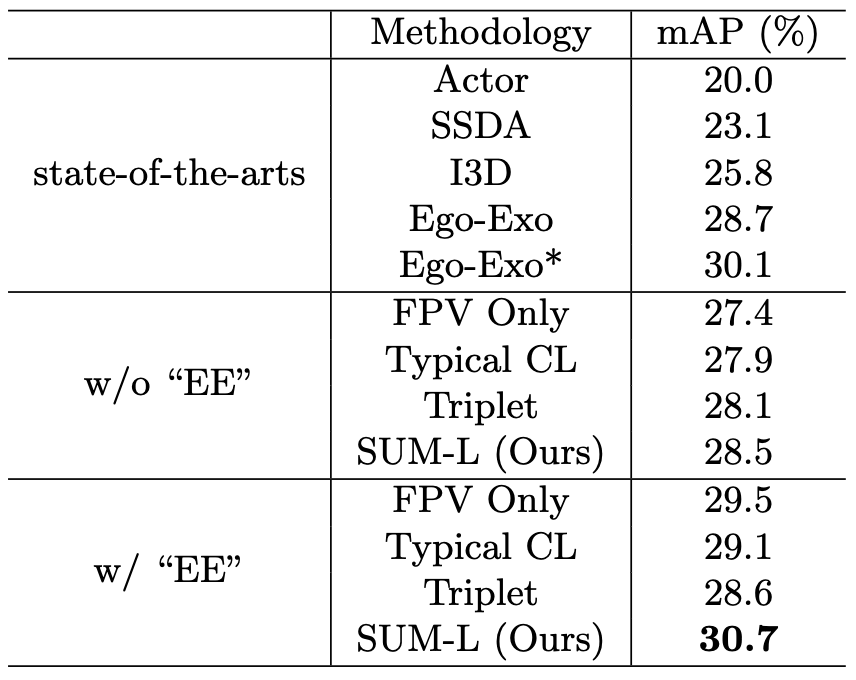
Comparisons on EPIC-Kitchens

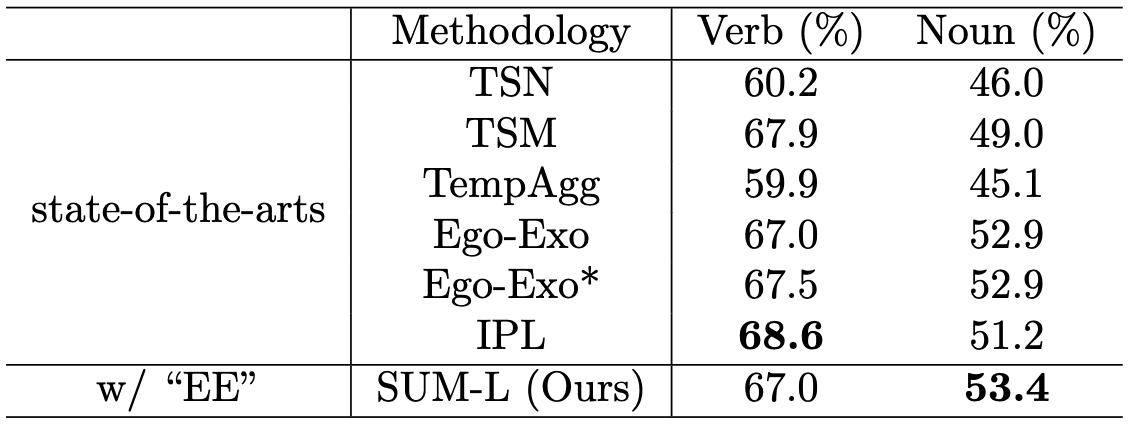
Comparisons on EPIC-Kitchens-100
Bibtex
@InProceedings{Wang_2023_ICCV,
author = {Wang, Qitong and Zhao, Long and Yuan, Liangzhe and Liu, Ting and Peng, Xi},
title = {Learning from Semantic Alignment between Unpaired Multiviews for Egocentric Video Recognition},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {3307-3317}
}